有A、B两个大文件,每个文件几十G,而内存只有4G,其中A文件存放学号+姓名,而B文件存放学号+分数,要求生成文件C,存放姓名和分数。怎么实现?
hash(学号)%1000,A到a0….a1000,B到b0~b1000
学号相同的人一定hash到相同序号的小文件
加载序号相同的小文件(比如:读取a2和b2)用map储存再按姓名+分数写入C即可
秒杀系统怎么设计 秒杀存在的问题
高并发、瞬间请求量极大
黄牛、黑客恶意请求
链接暴露问题
数据库压力问题
库存不足和超卖问题
如何解决这些问题
页面静态化
秒杀活动的页面,大多数内容都是固定不变的,如商品名称,商品图片等等,可以对活动页面做静态化处理,减少访问服务端的请求。秒杀用户会分布在全国各地,有的在上海,有的在深圳,地域相差很远,网速也各不相同。为了让用户最快访问到活动页面,可以使用CDN(Content Delivery Network,内容分发网络)。CDN可以让用户就近获取所需内容。
按钮至灰控制
秒杀活动开始前,按钮一般需要置灰的。只有时间到了,才能变得可以点击。这是防止,秒杀用户在时间快到的前几秒,疯狂请求服务器,然后秒杀时间点还没到,服务器就自己挂了。
服务单一职责
我们都知道微服务设计思想,也就是把各个功能模块拆分,功能那个类似的放一起,再用分布式的部署方式。
如用户登录相关的,就设计个用户服务,订单相关的就搞个订单服务,再到礼物相关的就搞个礼物服务等等。那么,秒杀相关的业务逻辑也可以放到一起,搞个秒杀服务,单独给它搞个秒杀数据库。
服务单一职责有个好处:如果秒杀没抗住高并发的压力,秒杀库崩了,服务挂了,也不会影响到系统的其他服务。
秒杀链接加盐
链接如果明文暴露的话,会有人获取到请求Url,提前秒杀了。因此,需要给秒杀链接加盐。可以把URL动态化,如通过MD5加密算法加密随机的字符串去做url。
限流
一般有两种方式限流:nginx限流和redis限流。
为了防止某个用户请求过于频繁,我们可以对同一用户限流;
为了防止黄牛模拟几个用户请求,我们可以对某个IP进行限流;
为了防止有人使用代理,每次请求都更换IP请求,我们可以对接口进行限流。
为了防止瞬时过大的流量压垮系统,还可以使用阿里的Sentinel、Hystrix组件进行限流。
分布式锁
可以使用redis分布式锁解决超卖问题。
使用Redis的SET EX PX NX + 校验唯一随机值,再删除释放锁。
为了更严谨,一般也是用lua脚本代替。lua脚本如下:
MQ异步处理
如果瞬间流量特别大,可以使用消息队列削峰,异步处理。用户请求过来的时候,先放到消息队列,再拿出来消费。
限流&降级&熔断
限流,就是限制请求,防止过大的请求压垮服务器;
降级,就是秒杀服务有问题了,就降级处理,不要影响别的服务;
熔断,服务有问题就熔断,一般熔断降级是一起出现。
产品上线出问题怎么定位错误
大量并发查询用户商品信息,MySQL压力大查询慢,保证速度怎么优化方案 读写分离
海量日志数据,提取出某日访问百度次数最多的那个IP。
可以考虑采用“分而治之”的思想,按照IP地址的Hash(IP)%1024值,把海量IP日志分别存储到1024个小文件中。这样,每个小文件最多包含4MB个IP地址
对于每一个小文件,可以构建一个IP为key,出现次数为value的Hash map,同时记录当前出现次数最多的那个IP地址
可以得到1024个小文件中的出现次数最多的IP,再依据常规的排序算法得到总体上出现次数最多的IP;
给定a、b两个文件,各存放50亿个url,每个url各占64字节,内存限制是4G,让你找出a、b文件共同的url? 方案1
遍历文件a,对每个url求取hash(url)%1000,然后根据所取得的值将url分别存储到1000个小文件(记为a0,a1,…,a999)中。这样每个小文件的大约为300M。
遍历文件b,采取和a相同的方式将url分别存储到1000小文件(记为b0,b1,…,b999)。这样处理后,所有可能相同的url都在对应的小文件(a0vsb0,a1vsb1,…,a999vsb999)中,不对应的小文件不可能有相同的url。然后我们只要求出1000对小文件中相同的url即可。
求每对小文件中相同的url时,可以把其中一个小文件的url存储到hash_set中。然后遍历另一个小文件的每个url,看其是否在刚才构建的hash_set中,如果是,那么就是共同的url,存到文件里面就可以了。
方案2 如果允许有一定的误差,使用布隆过滤器
一般内存不足而需要分析的数据又很大的问题都可以使用分治的思想,将数据hash(x)%1000分为小文件再分别加载小文件到内存中处理即可 如何保证接口的幂等性 什么是幂等性 幂等性是系统服务对外一种承诺,承诺只要调用接口成功,外部多次调用对系统的影响是一致的。声明为幂等的服务会认为外部调用失败是常态,并且失败之后必然会有重试。
什么情况下需要幂等 以SQL为例:
SELECT col1 FROM tab1 WHER col2=2,无论执行多少次都不会改变状态,是天然的幂等。
UPDATE tab1 SET col1=1 WHERE col2=2,无论执行成功多少次状态都是一致的,因此也是幂等操作。
UPDATE tab1 SET col1=col1+1 WHERE col2=2,每次执行的结果都会发生变化,这种不是幂等的。
insert into user(userid,name) values(1,’a’) 如userid为唯一主键,即重复操作上面的业务,只会插入一条用户数据,具备幂等性。
如userid不是主键,可以重复,那上面业务多次操作,数据都会新增多条,不具备幂等性。
delete from user where userid=1,多次操作,结果一样,具备幂等性
如何保证幂等 1、token机制
服务端提供了发送token的接口。我们在分析业务的时候,哪些业务是存在幂等问题的,就必须在执行业务前,先去获取token,服务器会把token保存到redis中。
然后调用业务接口请求时,把token携带过去,一般放在请求头部。
服务器判断token是否存在redis中,存在表示第一次请求,然后删除token,继续执行业务。
如果判断token不存在redis中,就表示是重复操作,直接返回重复标记给client,这样就保证了业务代码,不被重复执行。
关键点 先删除token,还是后删除token。
后删除token:如果进行业务处理成功后,删除redis中的token失败了,这样就导致了有可能会发生重复请求,因为token没有被删除。这个问题其实是数据库和缓存redis数据不一致问题,后续会写文章进行讲解。
先删除token:如果系统出现问题导致业务处理出现异常,业务处理没有成功,接口调用方也没有获取到明确的结果,然后进行重试,但token已经删除掉了,服务端判断token不存在,认为是重复请求,就直接返回了,无法进行业务处理了。
先删除token可以保证不会因为重复请求,业务数据出现问题。出现业务异常,可以让调用方配合处理一下,重新获取新的token,再次由业务调用方发起重试请求就ok了。
token机制缺点
业务请求每次请求,都会有额外的请求(一次获取token请求、判断token是否存在的业务)。其实真实的生产环境中,1万请求也许只会存在10个左右的请求会发生重试,为了这10个请求,我们让9990个请求都发生了额外的请求。
2、乐观锁机制
这种方法适合在更新的场景中,update t_goods set count = count -1 , version = version + 1 where good_id=2 and version = 1
根据version版本,也就是在操作库存前先获取当前商品的version版本号,然后操作的时候带上此version号。我们梳理下,我们第一次操作库存时,得到version为1,调用库存服务version变成了2;但返回给订单服务出现了问题,订单服务又一次发起调用库存服务,当订单服务传如的version还是1,再执行上面的sql语句时,就不会执行;因为version已经变为2了,where条件就不成立。这样就保证了不管调用几次,只会真正的处理一次。
乐观锁主要使用于处理读多写少的问题
3、唯一主键 这个机制是利用了数据库的主键唯一约束的特性,解决了在insert场景时幂等问题。但主键的要求不是自增的主键,这样就需要业务生成全局唯一的主键。
如果是分库分表场景下,路由规则要保证相同请求下,落地在同一个数据库和同一表中,要不然数据库主键约束就不起效果了,因为是不同的数据库和表主键不相关
4、防重表 使用订单号orderNo做为去重表的唯一索引,把唯一索引插入去重表,再进行业务操作,且他们在同一个事务中。这个保证了重复请求时,因为去重表有唯一约束,导致请求失败,避免了幂等问题。这里要注意的是,去重表和业务表应该在同一库中,这样就保证了在同一个事务,即使业务操作失败了,也会把去重表的数据回滚。这个很好的保证了数据一致性。
5、唯一ID 调用接口时,生成一个唯一id,redis将数据保存到集合中(去重),存在即处理过。
缓存和数据库不一致问题 更新缓存和更新数据库 大部分观点认为,做缓存不应该是去更新缓存,而是应该删除缓存,然后由下个请求去去缓存,发现不存在后再读取数据库,写入缓存。观点引用:《分布式之数据库和缓存双写一致性方案解析》孤独烟
原因一:线程安全角度同时有请求A和请求B进行更新操作,那么会出现(1)线程A更新了数据库(2)线程B更新了数据库(3)线程B更新了缓存(4)线程A更新了缓存这就出现请求A更新缓存应该比请求B更新缓存早才对,但是因为网络等原因,B却比A更早更新了缓存。这就导致了脏数据,因此不考虑。
原因二:业务场景角度有如下两点:
如果你是一个写数据库场景比较多,而读数据场景比较少的业务需求,采用这种方案就会导致,数据压根还没读到,缓存就被频繁的更新,浪费性能。
如果你写入数据库的值,并不是直接写入缓存的,而是要经过一系列复杂的计算再写入缓存。那么,每次写入数据库后,都再次计算写入缓存的值,无疑是浪费性能的。显然,删除缓存更为适合。
删缓存和更新数据库 先删缓存,再更新数据库 该方案会导致请求数据不一致同时有一个请求A进行更新操作,另一个请求B进行查询操作。那么会出现如下情形:
请求A进行写操作,删除缓存
请求B查询发现缓存不存在
请求B去数据库查询得到旧值
请求B将旧值写入缓存
请求A将新值写入数据库上述情况就会导致不一致的情形出现。
先更新数据库,再删缓存 这种情况不存在并发问题么?不是的。假设这会有两个请求,一个请求A做查询操作,一个请求B做更新操作,那么会有如下情形产生
缓存刚好失效
请求A查询数据库,得一个旧值
请求B将新值写入数据库
请求B删除缓存
请求A将查到的旧值写入缓存ok,如果发生上述情况,确实是会发生脏数据。 然而,发生这种情况的概率又有多少呢?发生上述情况有一个先天性条件,就是步骤(3)的写数据库操作比步骤(2)的读数据库操作耗时更短,才有可能使得步骤(4)先于步骤(5)。可是,大家想想,数据库的读操作的速度远快于写操作的(不然做读写分离干嘛,做读写分离的意义就是因为读操作比较快,耗资源少),因此步骤(3)耗时比步骤(2)更短,这一情形很难出现。
先更新数据库,再删缓存依然会有问题,不过,问题出现的可能性会因为上面说的原因,变得比较低!(补充说明:我用了“先更新数据库,再删缓存”且不设过期时间策略,会不会有问题呢?由于先缓存和更新数据库不是原子的,如果更新了数据库,程序歇逼,就没删缓存,由于没有过期策略,就永远脏数据了。)所以,如果你想实现基础的缓存数据库双写一致的逻辑,那么在大多数情况下,在不想做过多设计,增加太大工作量的情况下,请先更新数据库,再删缓存!
数据库和缓存数据强一致怎么办 没有办法做到绝对的一致性,这是由CAP理论决定的,缓存系统适用的场景就是非强一致性的场景,所以它属于CAP中的AP。所以,我们得委曲求全,可以去做到BASE理论中说的最终一致性。
大佬们给出了到达最终一致性的解决思路,主要是针对上面两种双写策略(先删缓存,再更新数据库/先更新数据库,再删缓存)导致的脏数据问题,进行相应的处理,来保证最终一致性。
缓存延时双删 步骤
先删除缓存
再写数据库
休眠500毫秒(根据具体的业务时间来定)
再次删除缓存。
那么,这个休眠500毫秒怎么确定的,具体该休眠多久呢? 针对上面的情形,读者应该自行评估自己的项目的读数据业务逻辑的耗时。然后写数据的休眠时间则在读数据业务逻辑的耗时基础上,加几百ms即可。这么做的目的,就是确保读请求结束,写请求可以删除读请求造成的缓存脏数据。
如果你用了mysql的读写分离架构怎么办? ok,在这种情况下,造成数据不一致的原因如下,还是两个请求,一个请求A进行更新操作,另一个请求B进行查询操作。
请求A进行写操作,删除缓存
请求A将数据写入数据库了,
请求B查询缓存发现,缓存没有值
请求B去从库查询,这时,还没有完成主从同步,因此查询到的是旧值
请求B将旧值写入缓存
数据库完成主从同步,从库变为新值上述情形,就是数据不一致的原因。还是使用双删延时策略。只是,睡眠时间修改为在主从同步的延时时间基础上,加几百ms。
采用这种同步淘汰策略,吞吐量降低怎么办? ok,那就将第二次删除作为异步的。自己起一个线程,异步删除。这样,写的请求就不用沉睡一段时间后了,再返回。这么做,加大吞吐量。
删缓存失败了怎么办:重试机制 看似问题都已经解决了,但其实,还有一个问题没有考虑到,那就是删除缓存的操作,失败了怎么办?比如延时双删的时候,第二次缓存删除失败了,那不还是没有清除脏数据吗?解决方案就是再加上一个重试机制,保证删除缓存成功
流程如下所示
更新数据库数据;
缓存因为种种问题删除失败
将需要删除的key发送至消息队列
自己消费消息,获得需要删除的key
继续重试删除操作,直到成功然而,
该方案有一个缺点,对业务线代码造成大量的侵入。
于是有了方案二,在方案二中,启动一个订阅程序去订阅数据库的binlog,获得需要操作的数据。在应用程序中,另起一段程序,获得这个订阅程序传来的信息,进行删除缓存操作
binlog 流程如下所示
更新数据库数据
数据库会将操作信息写入binlog日志当中
订阅程序提取出所需要的数据以及key
另起一段非业务代码,获得该信息
尝试删除缓存操作,发现删除失败
将这些信息发送至消息队列
重新从消息队列中获得该数据,重试操作。
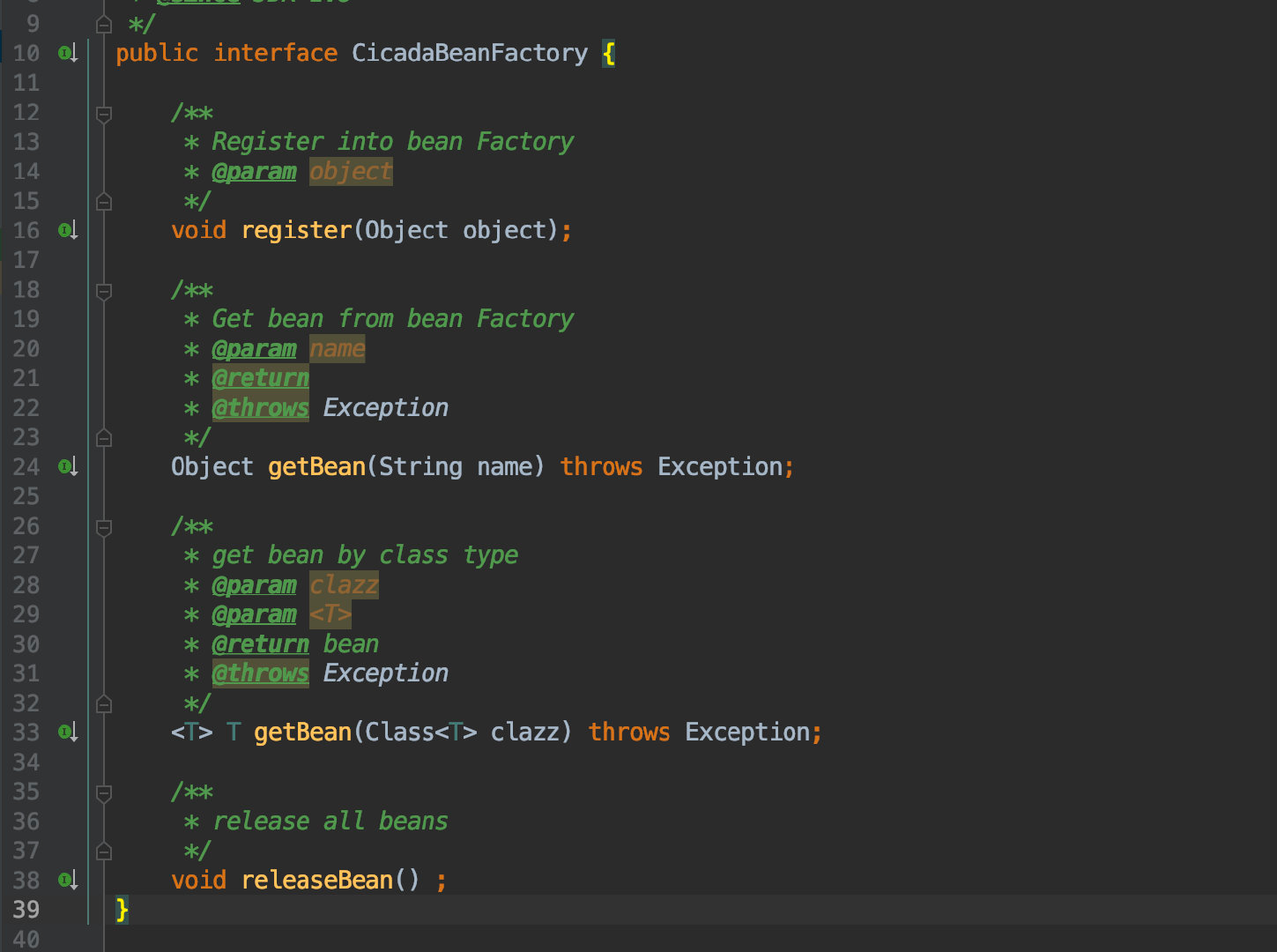
什么是SPI SPI 全称为 (Service Provider Interface) ,是JDK内置的一种服务提供发现机制
SPI 实践 接下来我们来如何来利用 SPI 实现刚才提到的可拔插 IOC 容器。
既然刚才都提到了 SPI 的本质就是面向接口编程,所以自然我们首先需要定义一个接口:
其中包含了一些 Bean 容器所必须的操作:注册、获取、释放 bean。
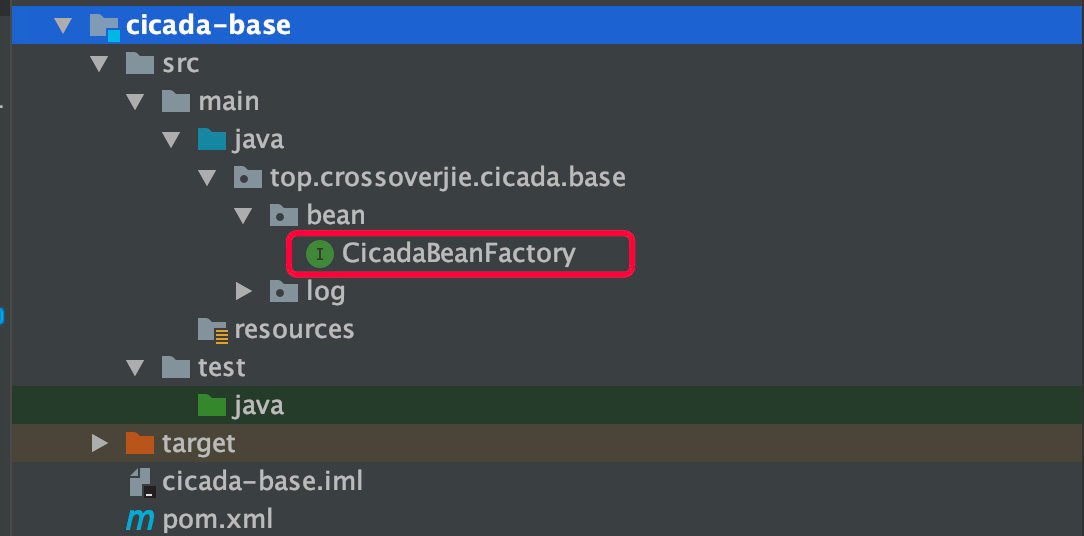
为了让其他人也能实现自己的 IOC 容器,所以我们将这个接口单独放到一个 Module 中,可供他人引入实现。
所以当我要实现一个单例的 IOC 容器时,我只需要新建一个 Module 然后引入刚才的模块并实现 CicadaBeanFactory 接口即可。
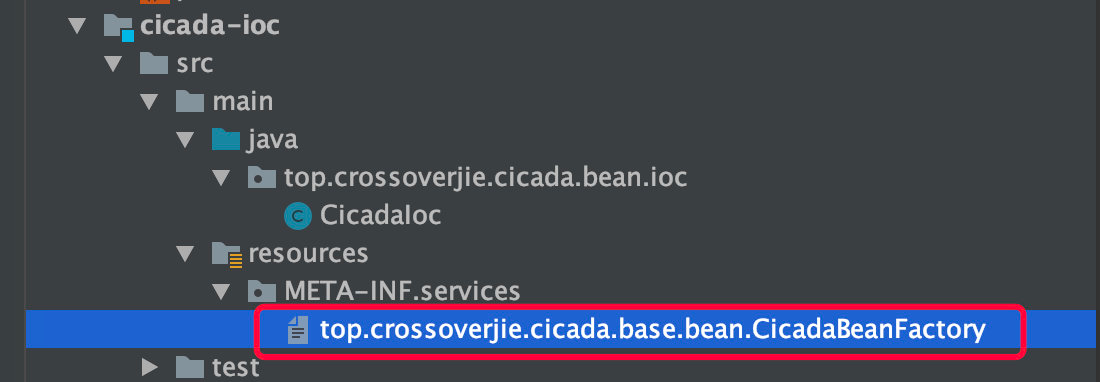
当然其中最重要的则是需要在 resources 目录下新建一个 META-INF/services/top.crossoverjie.cicada.base.bean.CicadaBeanFactory 文件,文件名必须得是我们之前定义接口的全限定名(SPI 规范)。
其中的内容便是我们自己实现类的全限定名:
top.crossoverjie.cicada.bean.ioc.CicadaIoc
可以想象最终会通过这里的全限定名来反射创建对象。
只不过这个过程 Java 已经提供 API 屏蔽掉了:
public static CicadaBeanFactory getCicadaBeanFactory () { ServiceLoader<CicadaBeanFactory> cicadaBeanFactories = ServiceLoader.load(CicadaBeanFactory.class); if (cicadaBeanFactories.iterator().hasNext()){ return cicadaBeanFactories.iterator().next() ; } return new CicadaDefaultBean (); }
当 classpath 中存在我们刚才的实现类(引入实现类的 jar 包),便可以通过 java.util.ServiceLoader 工具类来找到所有的实现类(可以有多个实现类同时存在,只不过通常我们只需要一个)。
一些都准备好之后,使用自然就非常简单了。
<dependency > <groupId > top.crossoverjie.opensource</groupId > <artifactId > cicada-ioc</artifactId > <version > 2.0.4</version > </dependency >
我们只需要引入这个依赖便能使用它的实现,当我们想换一种实现方式时只需要更换一个依赖即可。
这样就做到了不修改一行代码灵活的可拔插选择 IOC 容器了。
SPI 的一些其他应用
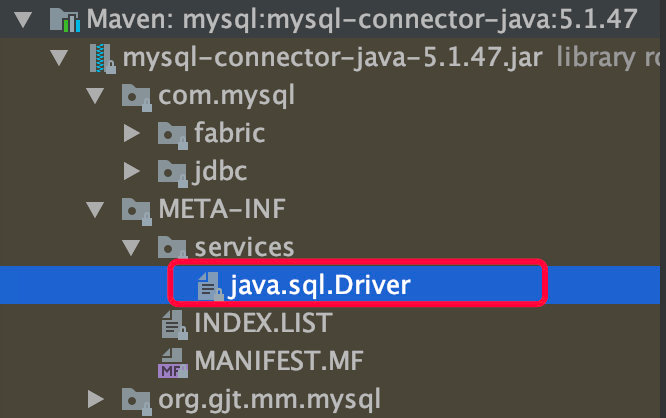
MySQL 的驱动包也是利用 SPI 来实现自己的连接逻辑。
总结来说:
提供一个接口
在resource下新建META-INF/services目录,在目录下新建接口的全限定名文件
服务方实现接口
调用ServiceLoad.load()
什么是RPC? RPC(Remote Procedure Call)远程过程调用,简单的理解是一个节点请求另一个节点提供的服务
首先客户端需要告诉服务器,需要调用的函数,这里函数和进程ID存在一个映射,客户端远程调用时,需要查一下函数,找到对应的ID,然后执行函数的代码。
客户端需要把本地参数传给远程函数,本地调用的过程中,直接压栈即可,但是在远程调用过程中不再同一个内存里,无法直接传递函数的参数,因此需要客户端把参数转换成字节流,传给服务端,然后服务端将字节流转换成自身能读取的格式,是一个序列化和反序列化的过程。
数据准备好了之后,如何进行传输?网络传输层需要把调用的ID和序列化后的参数传给服务端,然后把计算好的结果序列化传给客户端,因此TCP层即可完成上述过程,gRPC中采用的是HTTP2协议。
总结一下:
// Client端 // Student student = Call(ServerAddr, addAge, student) 1. 将这个调用映射为Call ID。 2. 将Call ID,student(params)序列化,以二进制形式打包 3. 把2中得到的数据包发送给ServerAddr,这需要使用网络传输层 4. 等待服务器返回结果 5. 如果服务器调用成功,那么就将结果反序列化,并赋给student,年龄更新 // Server端 1. 在本地维护一个Call ID到函数指针的映射call_id_map,可以用Map<String, Method> callIdMap 2. 等待客户端请求 3. 得到一个请求后,将其数据包反序列化,得到Call ID 4. 通过在callIdMap中查找,得到相应的函数指针 5. 将student(params)反序列化后,在本地调用addAge()函数,得到结果 6. 将student结果序列化后通过网络返回给Client
在微服务的设计中,一个服务A如果访问另一个Module下的服务B,可以采用HTTP REST传输数据,并在两个服务之间进行序列化和反序列化操作,服务B把执行结果返回过来。
由于HTTP在应用层中完成,整个通信的代价较高,远程过程调用中直接基于TCP进行远程调用,数据传输在传输层TCP层完成,更适合对效率要求比较高的场景,RPC主要依赖于客户端和服务端之间建立Socket链接进行,底层实现比REST更复杂。
RPC demo 客户端
public class RPCClient <T> { public static <T> T getRemoteProxyObj (final Class<?> serviceInterface, final InetSocketAddress addr) { return (T) Proxy.newProxyInstance(serviceInterface.getClassLoader(), new Class <?>[]{serviceInterface}, new InvocationHandler () { @Override public Object invoke (Object proxy, Method method, Object[] args) throws Throwable { Socket socket = null ; ObjectOutputStream output = null ; ObjectInputStream input = null ; try { socket = new Socket (); socket.connect(addr); output = new ObjectOutputStream (socket.getOutputStream()); output.writeUTF(serviceInterface.getName()); output.writeUTF(method.getName()); output.writeObject(method.getParameterTypes()); output.writeObject(args); input = new ObjectInputStream (socket.getInputStream()); return input.readObject(); }finally { if (socket != null ){ socket.close(); } if (output != null ){ output.close(); } if (input != null ){ input.close(); } } } }); } }
服务端
public class ServiceCenter implements Server { private static ExecutorService executor = Executors.newFixedThreadPool(Runtime.getRuntime().availableProcessors()); private static final HashMap<String, Class> serviceRegistry = new HashMap <String, Class>(); private static boolean isRunning = false ; private static int port; public ServiceCenter (int port) { ServiceCenter.port = port; } @Override public void start () throws IOException { ServerSocket server = new ServerSocket (); server.bind(new InetSocketAddress (port)); System.out.println("Server Start ....." ); try { while (true ){ executor.execute(new ServiceTask (server.accept())); } }finally { server.close(); } } @Override public void register (Class serviceInterface, Class impl) { serviceRegistry.put(serviceInterface.getName(), impl); } @Override public boolean isRunning () { return isRunning; } @Override public int getPort () { return port; } @Override public void stop () { isRunning = false ; executor.shutdown(); } private static class ServiceTask implements Runnable { Socket client = null ; public ServiceTask (Socket client) { this .client = client; } @Override public void run () { ObjectInputStream input = null ; ObjectOutputStream output = null ; try { input = new ObjectInputStream (client.getInputStream()); String serviceName = input.readUTF(); String methodName = input.readUTF(); Class<?>[] parameterTypes = (Class<?>[]) input.readObject(); Object[] arguments = (Object[]) input.readObject(); Class serviceClass = serviceRegistry.get(serviceName); if (serviceClass == null ){ throw new ClassNotFoundException (serviceName + "not found!" ); } Method method = serviceClass.getMethod(methodName, parameterTypes); Object result = method.invoke(serviceClass.newInstance(), arguments); output = new ObjectOutputStream (client.getOutputStream()); output.writeObject(result); }catch (Exception e){ e.printStackTrace(); }finally { if (output!=null ){ try { output.close(); }catch (IOException e){ e.printStackTrace(); } } if (input != null ) { try { input.close(); } catch (IOException e) { e.printStackTrace(); } } if (client != null ) { try { client.close(); } catch (IOException e) { e.printStackTrace(); } } } } } } public class ServiceProducerImpl implements ServiceProducer { @Override public String sendData (String data) { return "I am service producer!!!, the data is " + data; } } public class RPCTest { public static void main (String[] args) throws IOException { new Thread (new Runnable () { @Override public void run () { try { Server serviceServer = new ServiceCenter (8088 ); serviceServer.register(ServiceProducer.class, ServiceProducerImpl.class); serviceServer.start(); } catch (IOException e) { e.printStackTrace(); } } }).start(); ServiceProducer service = RPCClient.getRemoteProxyObj(ServiceProducer.class, new InetSocketAddress ("localhost" , 8088 )); System.out.println(service.sendData("test" )); } }
gRPC gRPC与REST
REST通常以业务为导向,将业务对象上执行的操作映射到HTTP动词,格式非常简单,可以使用浏览器进行扩展和传输,通过JSON数据完成客户端和服务端之间的消息通信,直接支持请求/响应方式的通信。不需要中间的代理,简化了系统的架构,不同系统之间只需要对JSON进行解析和序列化即可完成数据的传递。
但是REST也存在一些弊端,比如只支持请求/响应这种单一的通信方式,对象和字符串之间的序列化操作也会影响消息传递速度,客户端需要通过服务发现的方式,知道服务实例的位置,在单个请求获取多个资源时存在着挑战,而且有时候很难将所有的动作都映射到HTTP动词。
正是因为REST面临一些问题,因此可以采用gRPC作为一种替代方案,gRPC 是一种基于二进制流的消息协议,可以采用基于Protocol Buffer的IDL定义grpc API,这是Google公司用于序列化结构化数据提供的一套语言中立的序列化机制,客户端和服务端使用HTTP/2以Protocol Buffer格式交换二进制消息。
gRPC的优势是,设计复杂更新操作的API非常简单,具有高效紧凑的进程通信机制,在交换大量消息时效率高,远程过程调用和消息传递时可以采用双向的流式消息方式,同时客户端和服务端支持多种语言编写,互操作性强;不过gRPC的缺点是不方便与JavaScript集成,某些防火墙不支持该协议。
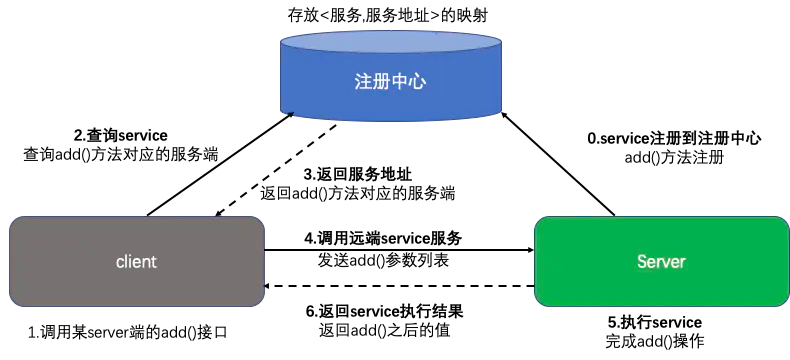
注册中心:当项目中有很多服务时,可以把所有的服务在启动的时候注册到一个注册中心里面,用于维护服务和服务器之间的列表,当注册中心接收到客户端请求时,去找到该服务是否远程可以调用,如果可以调用需要提供服务地址返回给客户端,客户端根据返回的地址和端口,去调用远程服务端的方法,执行完成之后将结果返回给客户端。这样在服务端加新功能的时候,客户端不需要直接感知服务端的方法,服务端将更新之后的结果在注册中心注册即可,而且当修改了服务端某些方法的时候,或者服务降级服务多机部署想实现负载均衡的时候,我们只需要更新注册中心的服务群即可。
demo 这里使用SpringBoot+gRPC的形式实现RPC调用过程 项目结构分为三部分:client、grpc、server
grpc
<dependency > <groupId > io.grpc</groupId > <artifactId > grpc-all</artifactId > <version > 1.12.0</version > </dependency >
<build > <extensions > <extension > <groupId > kr.motd.maven</groupId > <artifactId > os-maven-plugin</artifactId > <version > 1.4.1.Final</version > </extension > </extensions > <plugins > <plugin > <groupId > org.xolstice.maven.plugins</groupId > <artifactId > protobuf-maven-plugin</artifactId > <version > 0.5.0</version > <configuration > <pluginId > grpc-java</pluginId > <protocArtifact > com.google.protobuf:protoc:3.0.2:exe:${os.detected.classifier}</protocArtifact > <pluginArtifact > io.grpc:protoc-gen-grpc-java:1.2.0:exe:${os.detected.classifier}</pluginArtifact > </configuration > <executions > <execution > <goals > <goal > compile</goal > <goal > compile-custom</goal > </goals > </execution > </executions > </plugin > </plugins > </build >
创建.proto文件
syntax = "proto3" ; option java_package = "com.shgx.grpc.api" ;option java_outer_classname = "RPCDateServiceApi" ;option java_multiple_files = true ;package com.shgx.grpc.api;service RPCDateService { rpc getDate (RPCDateRequest) returns (RPCDateResponse) } message RPCDateRequest { string userName = 1 ; } message RPCDateResponse { string serverDate = 1 ; }
mvn complie
生成代码:
client
根据gRPC中的项目配置在client和server两个Module的pom.xml添加依赖
<dependency > <groupId > com.shgx</groupId > <artifactId > grpc</artifactId > <version > 0.0.1-SNAPSHOT</version > <scope > compile</scope > </dependency >
编写GRPCClient
public class GRPCClient { private static final String host = "localhost" ; private static final int serverPort = 9999 ; public static void main ( String[] args ) throws Exception { ManagedChannel managedChannel = ManagedChannelBuilder.forAddress( host, serverPort ).usePlaintext().build(); try { RPCDateServiceGrpc.RPCDateServiceBlockingStub rpcDateService = RPCDateServiceGrpc.newBlockingStub( managedChannel ); RPCDateRequest rpcDateRequest = RPCDateRequest .newBuilder() .setUserName("shgx" ) .build(); RPCDateResponse rpcDateResponse = rpcDateService.getDate( rpcDateRequest ); System.out.println( rpcDateResponse.getServerDate() ); } finally { managedChannel.shutdown(); } } }
server
按照2.2.3 client的方式添加依赖
创建RPCDateServiceImpl
public class RPCDateServiceImpl extends RPCDateServiceGrpc .RPCDateServiceImplBase{ @Override public void getDate (RPCDateRequest request, StreamObserver<RPCDateResponse> responseObserver) { RPCDateResponse rpcDateResponse = null ; Date now=new Date (); SimpleDateFormat simpleDateFormat = new SimpleDateFormat ("今天是" +"yyyy年MM月dd日 E kk点mm分" ); String nowTime = simpleDateFormat.format( now ); try { rpcDateResponse = RPCDateResponse .newBuilder() .setServerDate( "Welcome " + request.getUserName() + ", " + nowTime ) .build(); } catch (Exception e) { responseObserver.onError(e); } finally { responseObserver.onNext( rpcDateResponse ); } responseObserver.onCompleted(); } }
创建GRPCServer
public class GRPCServer { private static final int port = 9999 ; public static void main ( String[] args ) throws Exception { Server server = ServerBuilder. forPort(port) .addService( new RPCDateServiceImpl () ) .build().start(); System.out.println( "grpc服务端启动成功, 端口=" + port ); server.awaitTermination(); } }
一个优秀的RPC框架需要考虑的问题
微服务化应用都基于微服务化,实现资源调用离不开远程调用多实例问题 一个服务可能有多个实例,你在调用时,要如何获取这些实例的地址呢?— 这时候就需要一个服务注册中心,从服务注册中心获取服务的实例列表,再从中选择一个进行调用。负载均衡 选哪个调用好呢?这时候就需要负载均衡了,于是又得考虑如何实现复杂均衡缓存 总不能每次调用时都去注册中心查询实例列表吧,这样效率多低呀,于是又有了缓存,有了缓存,就要考虑缓存的更新问题异步调用 客户端总不能每次调用完都干等着服务端返回数据吧,于是就要支持异步调用;
版本控制 服务端的接口修改了,老的接口还有人在用,怎么办?总不能让他们都改了吧?这就需要版本控制了;线程池 服务端总不能每次接到请求都马上启动一个线程去处理吧?于是就需要线程池;未处理完的请求 服务端关闭时,还没处理完的请求怎么办?是直接结束呢,还是等全部请求处理完再关闭呢?
什么是DDD? MVC 要说DDD,不得不先看看MVC,我相信基本上99%的java开发读者,不管你是计科专业出身还是跨专业,初学spring或者springboot的时候,接触到的代码分层都是MVC
开发人员可以只关注整个结构中的其中某一层;
可以很容易的用新的实现来替换原有层次的实现;
可以降低层与层之间的依赖;
有利于标准化;
利于各层逻辑的复用。
但是真实情况是这样吗?随着你系统功能迭代,业务逻辑越来越复杂之后。MVC三层中,V层作为数据载体,C层作为逻辑路由都是很薄的一层,大量的代码都堆积在了M层(模型层)。一个service的类,动辄几百上千行,大的甚至几万行,逻辑嵌套复杂,主业务逻辑不清晰。service做的稍微轻量化一点的,代码就像是胶水,把数据库执行逻辑与控制返回给前端的逻辑胶在一起,主次不清晰。
那么DDD为什么可以去解决以上的问题呢? DDD核心思想是什么呢?解耦!让业务不是像炒大锅饭一样混在一起,而是一道道工序复杂的美食,都有他们自己独立的做法。
DDD的价值观里面,任何业务都是某个业务领域模型的职责体现。A领域只会去做A领域的事情,A领域想去修改B领域,需要找中介(防腐层)去对B领域完成操作。我想完成一个很长的业务逻辑动作,在划分好业务边界之后,交给业务服务的编排者(应用服务)去组织业务模型(聚合)完成逻辑。
这样,每个服务(领域)只会做自己业务边界内的事情,最小细粒度的去定义需求的实现。原先空空的贫血模型摇身一变变成了充血模型。原理冗长的service里面类似到处set,get值这种与业务逻辑无关的数据载体包装代码,都会被去除,进到应用服务层,你的代码就是你的业务逻辑。逻辑清晰,可维护性高!
什么样的系统适配DDD 中小规模的系统,本身业务体量小,功能单一,选择mvc架构无疑是最好的。 项目化交付的系统,研发周期短,一天到晚按照甲方的需求定制功能。
中大规模系统,产品化模式,业务可持续迭代,可预见的业务逻辑复杂性的系统。
DDD的代码怎么做 // TODO
Java实现生产者消费者 wait()和notify()方法的实现 public class Test1 { private static Integer count = 0 ; private static final Integer FULL = 10 ; private static String LOCK = "lock" ; public static void main (String[] args) { Test1 test1 = new Test1 (); new Thread (test1.new Producer ()).start(); new Thread (test1.new Consumer ()).start(); new Thread (test1.new Producer ()).start(); new Thread (test1.new Consumer ()).start(); new Thread (test1.new Producer ()).start(); new Thread (test1.new Consumer ()).start(); new Thread (test1.new Producer ()).start(); new Thread (test1.new Consumer ()).start(); } class Producer implements Runnable { @Override public void run () { for (int i = 0 ; i < 10 ; i++) { try { Thread.sleep(3000 ); } catch (Exception e) { e.printStackTrace(); } synchronized (LOCK) { while (count == FULL) { try { LOCK.wait(); } catch (Exception e) { e.printStackTrace(); } } count++; System.out.println(Thread.currentThread().getName() + "生产者生产,目前总共有" + count); LOCK.notifyAll(); } } } } class Consumer implements Runnable { @Override public void run () { for (int i = 0 ; i < 10 ; i++) { try { Thread.sleep(3000 ); } catch (InterruptedException e) { e.printStackTrace(); } synchronized (LOCK) { while (count == 0 ) { try { LOCK.wait(); } catch (Exception e) { } } count--; System.out.println(Thread.currentThread().getName() + "消费者消费,目前总共有" + count); LOCK.notifyAll(); } } } } }
可重入锁ReentrantLock的实现 public class Test2 { private static Integer count = 0 ; private static final Integer FULL = 10 ; private Lock lock = new ReentrantLock (); private final Condition notFull = lock.newCondition(); private final Condition notEmpty = lock.newCondition(); public static void main (String[] args) { Test2 test2 = new Test2 (); new Thread (test2.new Producer ()).start(); new Thread (test2.new Consumer ()).start(); new Thread (test2.new Producer ()).start(); new Thread (test2.new Consumer ()).start(); new Thread (test2.new Producer ()).start(); new Thread (test2.new Consumer ()).start(); new Thread (test2.new Producer ()).start(); new Thread (test2.new Consumer ()).start(); } class Producer implements Runnable { @Override public void run () { for (int i = 0 ; i < 10 ; i++) { try { Thread.sleep(3000 ); } catch (Exception e) { e.printStackTrace(); } lock.lock(); try { while (count == FULL) { try { notFull.await(); } catch (InterruptedException e) { e.printStackTrace(); } } count++; System.out.println(Thread.currentThread().getName() + "生产者生产,目前总共有" + count); notEmpty.signal(); } finally { lock.unlock(); } } } } class Consumer implements Runnable { @Override public void run () { for (int i = 0 ; i < 10 ; i++) { try { Thread.sleep(3000 ); } catch (InterruptedException e1) { e1.printStackTrace(); } lock.lock(); try { while (count == 0 ) { try { notEmpty.await(); } catch (Exception e) { e.printStackTrace(); } } count--; System.out.println(Thread.currentThread().getName() + "消费者消费,目前总共有" + count); notFull.signal(); } finally { lock.unlock(); } } } } }
阻塞队列BlockingQueue的实现 public class Test3 { private static Integer count = 0 ; final BlockingQueue blockingQueue = new ArrayBlockingQueue <>(10 ); public static void main (String[] args) { Test3 test3 = new Test3 (); new Thread (test3.new Producer ()).start(); new Thread (test3.new Consumer ()).start(); new Thread (test3.new Producer ()).start(); new Thread (test3.new Consumer ()).start(); new Thread (test3.new Producer ()).start(); new Thread (test3.new Consumer ()).start(); new Thread (test3.new Producer ()).start(); new Thread (test3.new Consumer ()).start(); } class Producer implements Runnable { @Override public void run () { for (int i = 0 ; i < 10 ; i++) { try { Thread.sleep(3000 ); } catch (Exception e) { e.printStackTrace(); } try { blockingQueue.put(1 ); count++; System.out.println(Thread.currentThread().getName() + "生产者生产,目前总共有" + count); } catch (InterruptedException e) { e.printStackTrace(); } } } } class Consumer implements Runnable { @Override public void run () { for (int i = 0 ; i < 10 ; i++) { try { Thread.sleep(3000 ); } catch (InterruptedException e1) { e1.printStackTrace(); } try { blockingQueue.take(); count--; System.out.println(Thread.currentThread().getName() + "消费者消费,目前总共有" + count); } catch (InterruptedException e) { e.printStackTrace(); } } } } }
信号量Semaphore的实现 public class Test4 { private static Integer count = 0 ; final Semaphore notFull = new Semaphore (10 ); final Semaphore notEmpty = new Semaphore (0 ); final Semaphore mutex = new Semaphore (1 ); public static void main (String[] args) { Test4 test4 = new Test4 (); new Thread (test4.new Producer ()).start(); new Thread (test4.new Consumer ()).start(); new Thread (test4.new Producer ()).start(); new Thread (test4.new Consumer ()).start(); new Thread (test4.new Producer ()).start(); new Thread (test4.new Consumer ()).start(); new Thread (test4.new Producer ()).start(); new Thread (test4.new Consumer ()).start(); } class Producer implements Runnable { @Override public void run () { for (int i = 0 ; i < 10 ; i++) { try { Thread.sleep(3000 ); } catch (InterruptedException e) { e.printStackTrace(); } try { notFull.acquire(); mutex.acquire(); count++; System.out.println(Thread.currentThread().getName() + "生产者生产,目前总共有" + count); } catch (InterruptedException e) { e.printStackTrace(); } finally { mutex.release(); notEmpty.release(); } } } } class Consumer implements Runnable { @Override public void run () { for (int i = 0 ; i < 10 ; i++) { try { Thread.sleep(3000 ); } catch (InterruptedException e1) { e1.printStackTrace(); } try { notEmpty.acquire(); mutex.acquire(); count--; System.out.println(Thread.currentThread().getName() + "消费者消费,目前总共有" + count); } catch (InterruptedException e) { e.printStackTrace(); } finally { mutex.release(); notFull.release(); } } } } }
Java实现BlockQueue public class BlockingQueue <E> { private Object[] elements; private int head = 0 , tail = 0 ; private int size; private ReentrantLock lock = new ReentrantLock (); private Condition notEmpty = lock.newCondition(); private Condition notFull = lock.newCondition(); public BlockingQueue (int capacity) { this .elements = new Object [capacity]; } public void put (E e) { lock.lock(); try { while (size == elements.length) notFull.await(); elements[tail] = e; if (++tail == elements.length) { tail = 0 ; } size++; notEmpty.signal(); } catch (InterruptedException ex) { ex.printStackTrace(); } finally { lock.unlock(); } } public E take () { lock.lock(); E e = null ; try { while (size == 0 ) { notEmpty.await(); } e = (E) elements[head]; elements[head] = null ; if (++head == elements.length) head = 0 ; size--; notFull.signal(); } catch (InterruptedException ex) { ex.printStackTrace(); } finally { lock.unlock(); } return e; } public int size () { lock.lock(); try { return size; } finally { lock.unlock(); } } }
解决哈希冲突的方法 开放定址法 从发生冲突的那个单元起,按照一定的次序,从哈希表中找到一个空闲的单元。然后把发生冲突的元素存入到该单元的一种方法。开放定址法需要的表长度要大于等于所需要存放的元素。
在开放定址法中解决冲突的方法有:线行探查法、平方探查法、双散列函数探查法。
开放定址法的缺点在于删除元素的时候不能真的删除,否则会引起查找错误,只能做一个特殊标记。只到有下个元素插入才能真正删除该元素。
线行探查法 线行探查法是开放定址法中最简单的冲突处理方法,它从发生冲突的单元起,依次判断下一个单元是否为空,当达到最后一个单元时,再从表首依次判断。直到碰到空闲的单元或者探查完全部单元为止。
可以参考csdn上flash对该方法的演示:http://student.zjzk.cn/course_ware/data_structure/web/flash/cz/kfdzh.swf
平方探查法 平方探查法即是发生冲突时,用发生冲突的单元d[i], 加上 1²、 2²等。即d[i] + 1²,d[i] + 2², d[i] + 3²…直到找到空闲单元。
在实际操作中,平方探查法不能探查到全部剩余的单元。不过在实际应用中,能探查到一半单元也就可以了。若探查到一半单元仍找不到一个空闲单元,表明此散列表太满,应该重新建立。
双散列函数探查法 这种方法使用两个散列函数hl和h2。其中hl和前面的h一样,以关键字为自变量,产生一个0至m—l之间的数作为散列地址;h2也以关键字为自变量,产生一个l至m—1之间的、并和m互素的数(即m不能被该数整除)作为探查序列的地址增量(即步长),探查序列的步长值是固定值l;对于平方探查法,探查序列的步长值是探查次数i的两倍减l;对于双散列函数探查法,其探查序列的步长值是同一关键字的另一散列函数的值。
链地址法(拉链法) 链接地址法的思路是将哈希值相同的元素构成一个同义词的单链表,并将单链表的头指针存放在哈希表的第i个单元中,查找、插入和删除主要在同义词链表中进行。链表法适用于经常进行插入和删除的情况。
如下一组数字,(32、40、36、53、16、46、71、27、42、24、49、64)哈希表长度为13,哈希函数为H(key)=key%13,则链表法结果如下:
0 1 -> 40 -> 27 -> 53 2 3 -> 16 -> 42 4 5 6 -> 32 -> 71 7 -> 46 8 9 10 -> 36 -> 49 11 -> 24 12 -> 64
注:在java中,链接地址法也是HashMap解决哈希冲突的方法之一,jdk1.7完全采用单链表来存储同义词,jdk1.8则采用了一种混合模式,对于链表长度大于8的,会转换为红黑树存储。
再哈希法 就是同时构造多个不同的哈希函数:
Hi = RHi(key) i= 1,2,3 … k;
当H1 = RH1(key) 发生冲突时,再用H2 = RH2(key) 进行计算,直到冲突不再产生,这种方法不易产生聚集,但是增加了计算时间。
建立公共溢出区 将哈希表分为公共表和溢出表,当溢出发生时,将所有溢出数据统一放到溢出区。
排行榜设计 基于数据库 基于MySQL,order by
缺点:
基于Redis 主要考察sort set 也就是zset
zadd添加数据后,zrevrange获取排序后的排名
类似于微信计数榜,如何设计不同用户看到的朋友圈的排行榜不一样 key的设计比较重要,比如aa用户和bb用户
zadd step:aa 1000 小明 zadd step:bb 1000 小明
同理时间也可以通过key的设计解决
zadd step:aa:20210929 1000 小明 zadd step:aa:20210929 1000 小明
但是上述设计会导致每个用户都有一个排行榜,存储的数据巨大,其实可以考虑只在用户查询时通过好友关系去生成
那朋友圈排行榜的:微信头像、点赞数 怎么获取呢
可以使用hmset hash储存对象,需要时通过zset储存的key去查询即可
最近七天排行榜怎么弄 前面我们说的都是每日排行榜。
假设面试官要求我们提供一个最近七天、上一周、上一月、上个季度、这一年排行榜啥的,又该怎么搞呢?
其实这还是在考察你对于 Redis 有序集合 API 的掌握程度。
也就是这个 API:
zinterstore/zunionstore destination numkeys key [key …] [weights weight [weight …]] [aggregate sum|min|max] 获取交集/并集
zinterstore/zunionstore其实就是交集/并集
destination 将交集/并集的结果保存到这个键中
numkeys 需要做交集/并集的集合的个数
key [key …] 具体参与交集/并集的集合
weights weight [weight …] 每个参与计算的集合的权重。在做交集/并集计算时,每个集合中的 member 会把自己的 score 乘以这个权重,默认为 1。
aggregate sum|min|max 对于各个集合中的相同元素是 sum(求和)、min(取最小值)还是max(取最大值),默认为 sum。
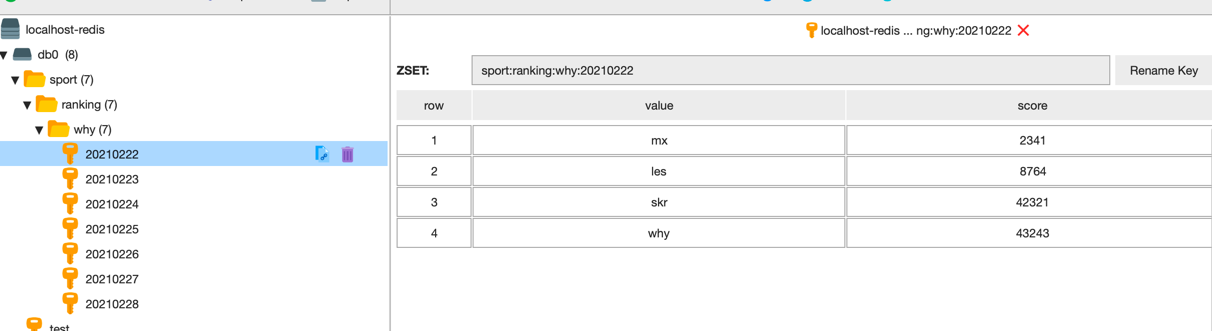
比如现在有一些数据
zadd sport:ranking:why:20210222 43243 why 2341 mx 8764 les 42321 skr zadd sport:ranking:why:20210223 57632 why 24354 mx 4231 les 43512 skr 5341 jay zadd sport:ranking:why:20210224 10026 why 12344 mx 54312 les 34531 skr 43512 jay zadd sport:ranking:why:20210225 54312 why 32451 mx 23412 les 21341 skr 56321 jay zadd sport:ranking:why:20210226 3212 why 63421 mx 53652 les 45621 skr 5723 jay zadd sport:ranking:why:20210227 5462 why 10158 mx 30169 les 48858 skr 66079 jay zadd sport:ranking:why:20210228 43553 why 4451 mx 7431 les 9563 skr 8232 jay
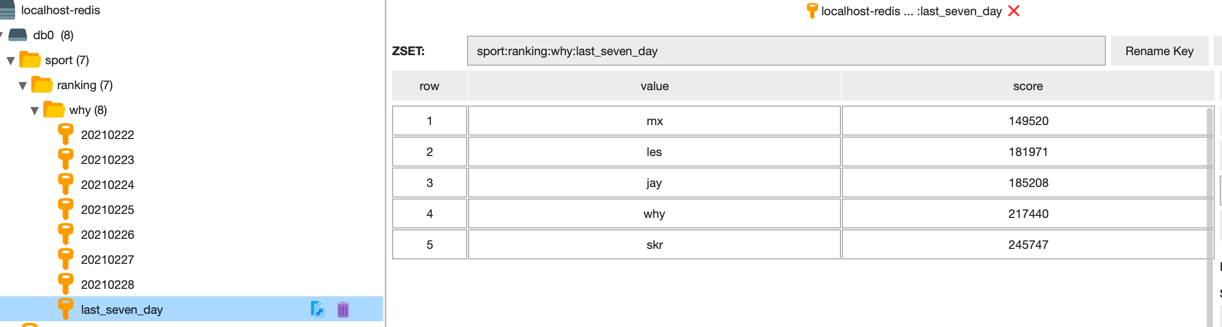
现在我们要求出最近 7 天的排行榜,就用下面这行命令,命令有点复杂,但是对着命令格式看,还是很清晰的:
zunionstore sport:ranking:why:last_seven_day 7 sport:ranking:why:20210222 sport:ranking:why:20210223 sport:ranking:why:20210224 sport:ranking:why:20210225 sport:ranking:why:20210226 sport:ranking:why:20210227 sport:ranking:why:20210228 weights 1 1 1 1 1 1 1 aggregate sum
上面用的是并集,如果我们的要求是对最近 7 天,每天都上传运动数据的人进行排序,就用交集来算。
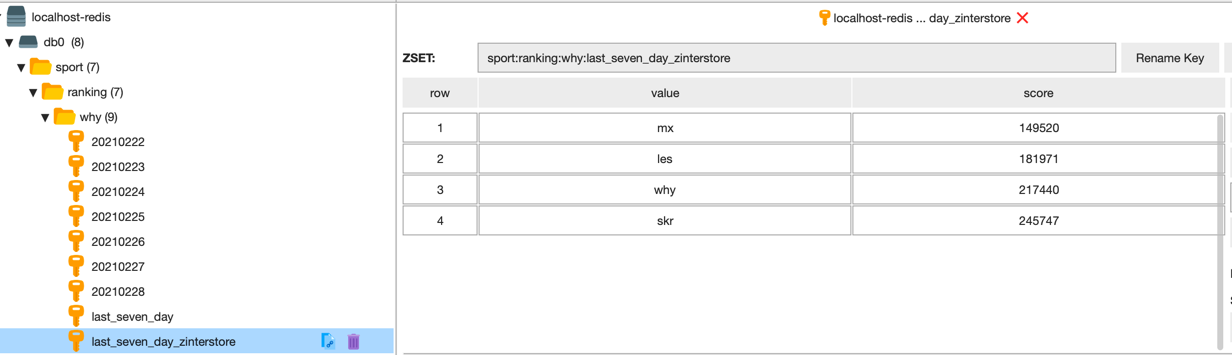
命令和上面的一致,只是把 zunionstore 修改为 zinterstore 即可。
另外为了有对比,合并之后的队列名称也修改一下,命令如下:
zinterstore sport:ranking:why:last_seven_day_zinterstore 7 sport:ranking:why:20210222 sport:ranking:why:20210223 sport:ranking:why:20210224 sport:ranking:why:20210225 sport:ranking:why:20210226 sport:ranking:why:20210227 sport:ranking:why:20210228 weights 1 1 1 1 1 1 1 aggregate sum
知道最近 7 天的做法了,我们又有每一天数据,上一周、上一月、上个季度、这一年排行榜啥的不都是这个套路吗
亿级用户排行榜 按段位分桶 由于数据量比较大,所以需要类似于分成一个个小文件的思想去统计每一部分的数据
比如游戏里的段位,统计国服前100,可以把王者、大师、砖石、铂金、黄金、白银、青铜 分为不同的桶,每个分段的人在不同的桶里(假设还是用zset存储用户的段位)
计算top100 分桶后,直接在段位最大的桶里计算top100即可
按积分分桶 [0-5000] [5001-10000] …..[10000000-x]
这种可能会出现热点问题,比如处于0-5000区间的人会非常多(可能很多人都是没有打排位)用户的落点其实并不是均匀的,那就需要通过其他预测算法去预估每个区间的人数了