
本地消息表事务:10Wqps高并发分布式事务的终极方案
分布式事务的背景
首先说说 分布式事务的背景。
传统单体架构下,所有的功能模块都在一个应用下,所有的代码和 业务逻辑 都在同一个应用下实现,所以保证数据的一致性就很简单,保证相关操作都在同一个本地事务下就可以了。
但是在微服务架构下,将一个应用拆分成了多个独立的服务,每个服务都能有自己的 数据库 ,服务间通信都是通过远程调用实现,实现一个功能可能需要由几个不同的服务来共同实现。
这就会带来一个问题,不同的服务之间无法做到使用同一个事务,这就无法保证数据的一致性了。
这就需要 分布式事务。
最直接、最简单、最粗暴的解决分布式事务的方式, 就是直接使用 Seata。
Seata 分布式事务方案
Seata 是一个 开源 的分布式事务解决方案,用于解决分布式系统中的数据一致性问题。
seata中,常用的有两种分布式事务实现方案,AT 及 TCC
AT模式主要关注多 DB 访问的数据一致性,当然也包括多服务下的多 DB 数据访问一致性问题
TCC 模式主要关注业务拆分,在按照业务横向扩展资源时,解决微服务间调用的一致性问题
AT模式(业务侵入小)
Seata AT模式是基于XA事务演进而来的一个分布式事务中间件,
XA是一个基于数据库实现的分布式事务协议,本质上和两阶段提交一样,需要数据库支持,Mysql5.6以上版本支持XA协议,其他数据库如Oracle,DB2也实现了XA接口
AT模式角色如下
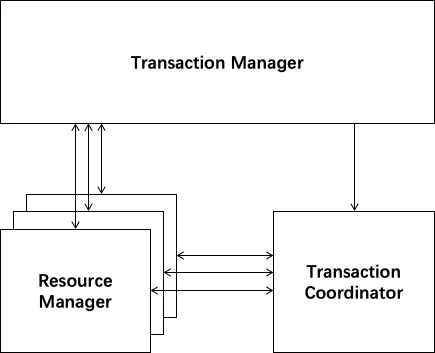
1、Transaction Coordinator (TC):事务协调器,维护全局事务的运行状态,负责协调并驱动全局事务的提交或回滚
2、Transaction Manager ™:
控制全局事务的边界,负责开启一个全局事务,并最终发起全局提交或全局回滚的决议
3、Resource Manager (RM):
控制分支事务,负责分支注册、状态汇报,并接收事务协调器的指令,驱动分支(本地)事务的提交和回滚
分支事务 基本处理逻辑如下
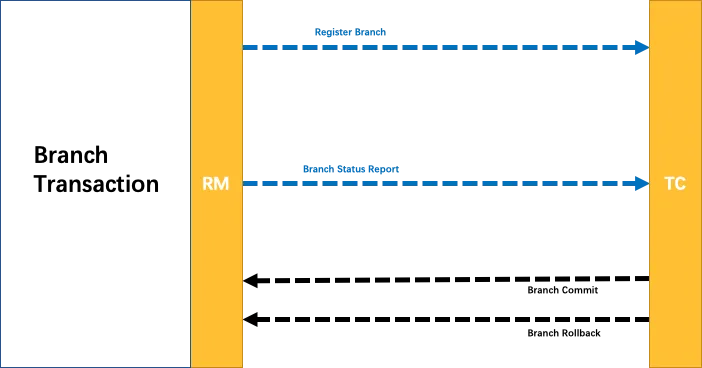
Branch就是指的分布式事务中每个独立的本地局部事务.
Seata TCC基本原理
AT模式的依赖的还是依赖单个服务或单个数据源自己的事务控制(分支事务),采用的是wal的思想,提交事务的时候同时记录undolog,如果全局事务成功,则删除undolog,如果失败,则使用undolog的数据回滚分支事务,最后删除undolog。
Seata TCC模式的流程图
TCC模式的特点是不再依赖于undolog,但是还是采用2阶段提交的方式:
第一阶段使用prepare尝试事务提交,第二阶段使用commit或者rollback让事务提交或者回滚。
引用网上一张TCC原理的参考图片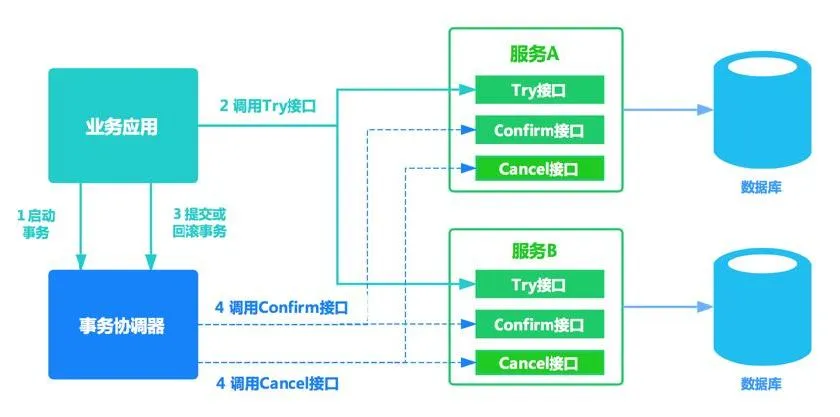
Seata TCC 事务的3个操作
TCC 将事务提交分为 Try - Confirm - Cancel 3个操作。
其和两阶段提交有点类似,Try为第一阶段,Confirm - Cancel为第二阶段,是一种应用层面侵入业务的两阶段提交。
| 操作方法 | 含义 |
|---|---|
| Try | 预留业务资源/数据效验 |
| Confirm | 确认执行业务操作,实际提交数据,不做任何业务检查,try成功,confirm必定成功,需保证幂等 |
| Cancel | 取消执行业务操作,实际回滚数据,需保证幂等 |
其核心在于将业务分为两个操作步骤完成。不依赖 RM 对分布式事务的支持,而是通过对业务逻辑的分解来实现分布式事务。
seata 压力测试的几个核心指标
CP (强一致)和AP(高并发)的 根本冲突
从上面的指标数据可以知道, Seata AT/TCC是 强一致,并发能力弱。
CP (强一致)和AP(高并发)是一对 根本矛盾,存在根本冲突。
10Wqps 的高并发事务,并不是CP,而是属于AP 高并发。Seata 如果不做特殊改造, 很难满足。
CAP 定理
CAP 该定理指出一个 分布式系统 最多只能同时满足一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance)这三项中的两项。
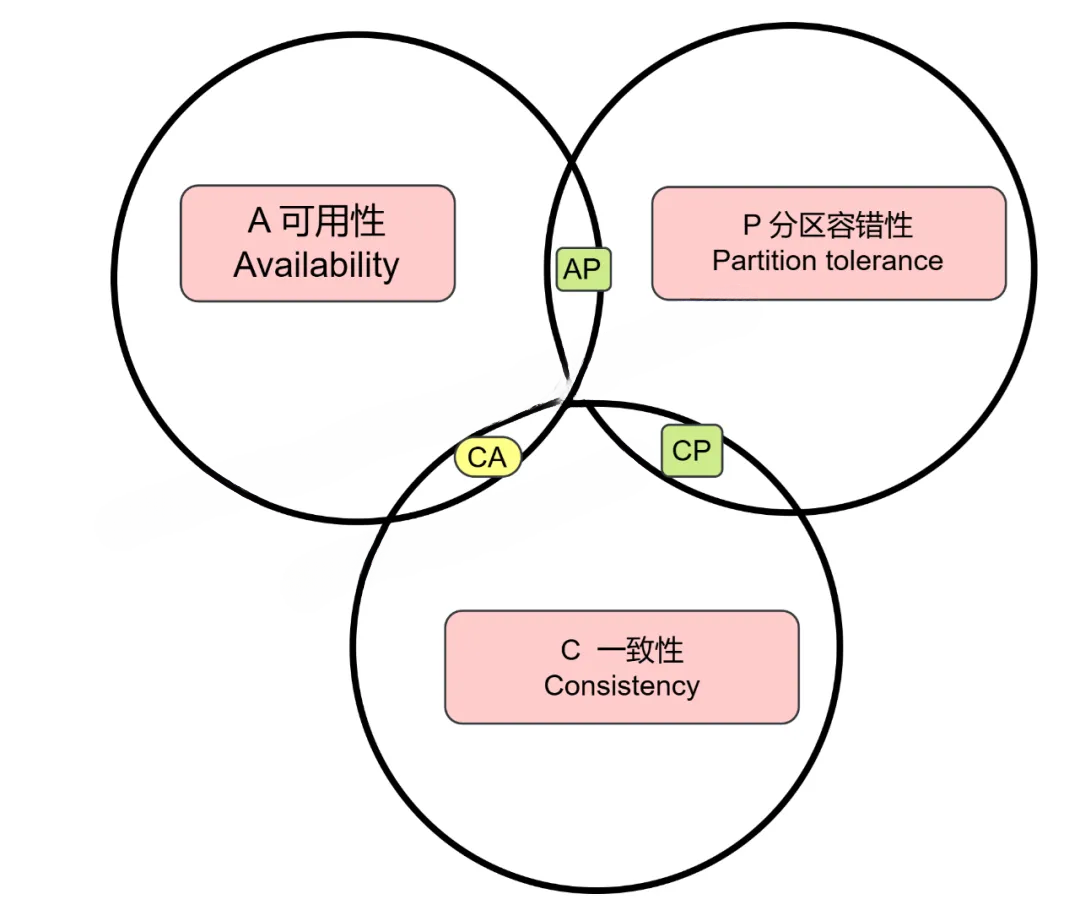
CAP定理的三个要素可以用来描述分布式系统的一致性和可用性。
如果事务要追求高并发,根据cap定理,需要放弃强一致性,只需要保证数据的最终一致性。
所以,在实践可以使用本地消息表的方案来解决分布式事务问题。
经典ebay 本地消息表方案
本地消息表方案最初是ebay提出的,其实也是BASE理论的应用,属于可靠消息最终一致性的范畴。
其概念图如下: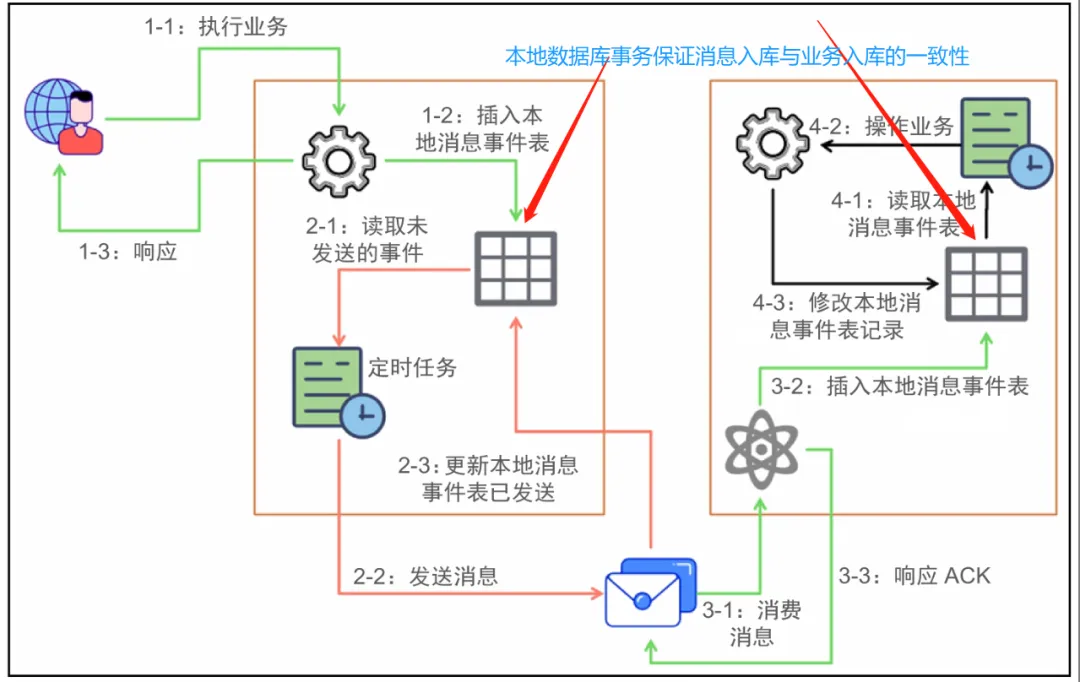
消息生产方/ 消息消费方,需要额外建一个消息表,并记录消息发送状态。
这里是拆分出来了多个本地消息表,看自己的业务。
如果规模比较小,可以只创建一个本地消息表。
如果规模比较大,可以 创建多个本地消息表。
这里为了表达方便, 只在 生产方创建一个本地消息表. 本地消息表的设计如下
| 字段 | 类型 | 注释 |
|---|---|---|
| id | long | id |
| msg_type | varchar | 消息类型 |
| biz_id | varchar | 业务唯一标志 |
| content | text | 消息体 |
| state | varchar | 状态(待发送,已消费) |
| create_time | datetime | 创建时间 |
| update_time | datetime | 更新时间 |
消息表和业务数据要在一个事务里提交,也就是说他们要在一个数据库里面。
然后消息会经过MQ发送到消息的消费方。如果消息发送失败,会进行重试发送。
消息消费方 需要处理这个消息,并完成自己的业务逻辑。
此时如果本地事务处理成功,表明已经处理成功了,如果处理失败,那么就会重试执行。
如果是业务上面的失败,可以给生产方发送一个业务补偿消息,通知生产方进行回滚等操作。
经典ebay 本地消息表步骤
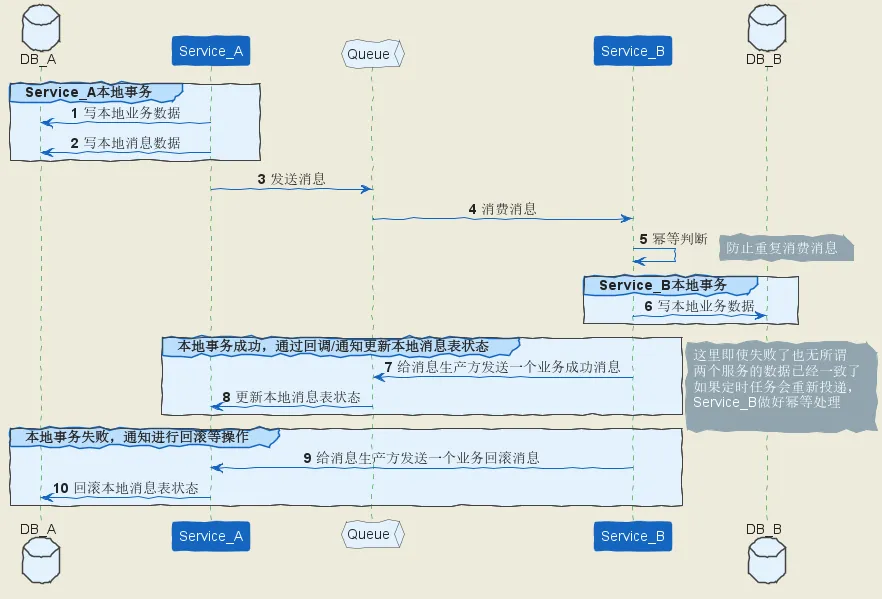
生产方定时扫描本地消息表,把还没处理完成的消息或者失败的消息再发送一遍。
发送消息方:
需要有一个消息表,记录着消息状态相关信息。
业务数据和消息表在同一个数据库,要保证它俩在同一个本地事务。直接利用本地事务,将业务数据和事务消息直接写入数据库。
在本地事务中处理完业务数据和写消息表操作后,通过写消息到 MQ 消息队列。使用专门的投递工作线程进行事务消息投递到MQ,根据投递ACK去删除事务消息表记录
消息会发到消息消费方,如果发送失败,即进行重试。
消息消费方:
处理消息队列中的消息,完成自己的业务逻辑。
如果本地事务处理成功,则表明已经处理成功了。
如果本地事务处理失败,那么就会重试执行。
如果是业务层面的失败,给消息生产方发送一个业务补偿消息,通知进行回滚等操作。
生产方和消费方定时扫描本地消息表,把还没处理完成的消息或者失败的消息再发送一遍。
经典ebay本地消息表 自动对账逻辑:
经典ebay本地消息表方案中,还设计了靠谱的自动对账补账逻辑,确保数据的最终一致性。
如果有靠谱的自动对账逻辑,这种方案还是非常实用的。
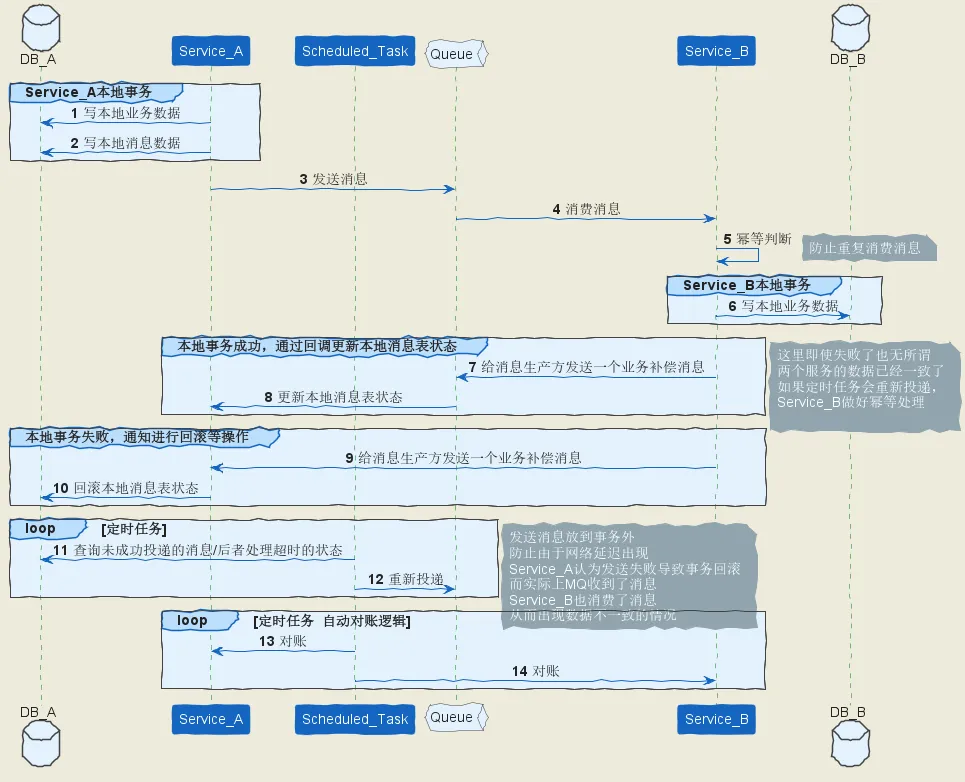
经典ebay本地消息表 的注意事项
使用本地消息表实现分布式事务可以确保消息在分布式环境中的可靠传递和一致性。
然而,需要注意以下几点:
消息的幂等性: 消费者一定需要保证接口的幂等性,消息的幂等性非常重要,以防止消息重复处理导致的数据不一致。
本地消息表的设计: 本地消息表的设计需要考虑到消息状态、重试次数、创建时间等字段,以便实现消息的跟踪和管理。
定时任务和重试机制: 需要实现定时任务或者重试机制来确保消息的可靠发送和处理。
经典ebay本地消息表 访问的 优点和缺点:
优点:
本地消息表建设成本比较低,实现了可靠消息的传递确保了分布式事务的最终一致性。
无需提供回查方法,进一步减少的业务的侵入。
在某些场景下,还可以进一步利用注解等形式进行解耦,有可能实现无业务代码侵入式的实现。
缺点:
本地消息表与业务耦合在一起,难于做成通用性,不可独立伸缩。
本地消息表是基于数据库来做的,而数据库是要读写磁盘IO的,因此在高并发下是有性能瓶颈的
数据大时,消息积压问题,扫表效率慢
数据大时,事务表数据爆炸,定时扫表存在延迟问题
经典ebay本地消息表 事务表数据爆炸 问题
经典ebay本地消息表 事务表数据爆炸, 定时任务扫表会很慢,存在巨大的延迟问题
解决的方案如下:
1:索引优化:在消息表中对状态字段增加索引,以加速扫表操作。索引可以加速消息的检索和筛选,从而提高操作效率。
2:分页查询:将扫表操作划分为多次分页查询,避免一次性查询大量数据造成的性能问题。
3:多线程 + 分段查询:
如果有业务标识,可以通过业务标识进行多线程分段扫表查询。
如果没有业务标识可以按区间查询比如线程1查询0-1000的数据,线程2查询1001-2000的数据。
4:表较大时进行分库分表:如果表较大可以进行分库分表操作。
除了在数据上折腾来折腾去, 能不能从本质上解决问题呢?
来一个 本质飞跃的答案:使用 Rocketmq消息topic 代替数据库的表。
本地消息表的升级:使用 Rocketmq消息topic 代替数据库的表
经典ebay 本地消息表 方案中,使用 数据库表用于保证最终一致性。
它的做法通常是在数据库中创建一张专门的表来记录业务操作产生的消息,然后通过定时任务等机制去扫描并处理这些消息,以确保相关操作在不同服务或模块间最终达成一致。
数据库的特点是:吞吐量低、性能低。
如何对本地消息表的升级,提高 本地消息操作的 吞吐量、并发量?
可以使用 RocketMQ 消息 Topic 来代替数据库的本地消息表。Rocketmq 可以轻松实现 10Wtps,而且能保证消息的可靠性、原子性。
核心思路是利用消息队列的可靠消息传递、异步处理等特性,将原本存储在本地消息表中的消息内容,以消息的形式发布到 RocketMQ 的特定 Topic 中,让各个消费者去订阅并处理这些消息,从而实现类似的最终一致性保障,同时避免了直接操作数据库表带来的低性能问题。
基于单向事务消息 的本地消息表方案
首先介绍一点基础知识:Rocketmq MQ事务消息。
基础知识:Rocketmq 的MQ事务消息方案
首先来看看 Rocketmq的 事务消息方案。
基于MQ的事务消息方案主要依靠MQ的半消息机制来实现投递消息和参与者自身本地事务的一致性保障。半消息机制实现原理其实借鉴的2PC的思路,是二阶段提交的广义拓展。
半消息:在原有队列消息执行后的逻辑,如果后面的本地逻辑出错,则不发送该消息,如果通过则告知MQ发送;
流程
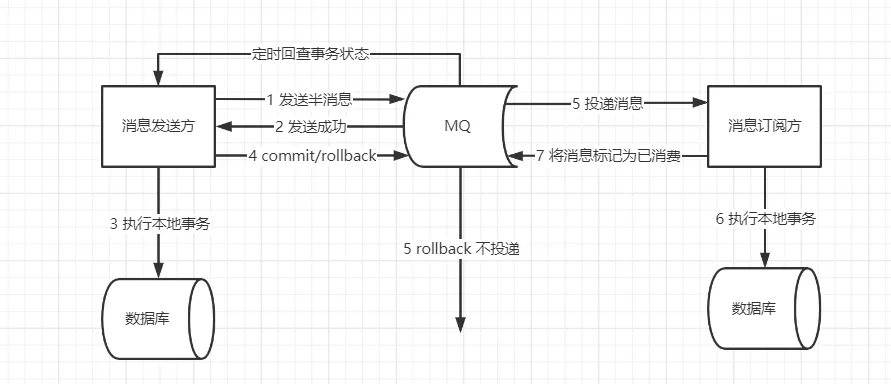
事务发起方首先发送半消息到MQ;
MQ通知发送方消息发送成功;
在发送半消息成功后执行本地事务;
根据本地事务执行结果返回commit或者是rollback;
如果消息是rollback, MQ将丢弃该消息不投递;如果是commit,MQ将会消息发送给消息订阅方;
订阅方根据消息执行本地事务;
订阅方执行本地事务成功后再从MQ中将该消息标记为已消费;
如果执行本地事务过程中,执行端挂掉,或者超时,MQ服务器端将不停的询问producer来获取事务状态;
Consumer端的消费成功机制有MQ保证;
Rocketmq 的MQ事务消息方案使用示例
举个例子,假设存在业务规则:某笔订单成功后,为用户加一定的积分。
在这条规则里,管理订单数据源的服务为事务发起方,管理积分数据源的服务为事务跟随者。
从这个过程可以看到,基于消息队列实现的事务存在以下操作:
订单服务创建订单,提交本地事务
订单服务发布一条消息
积分服务收到消息后加积分
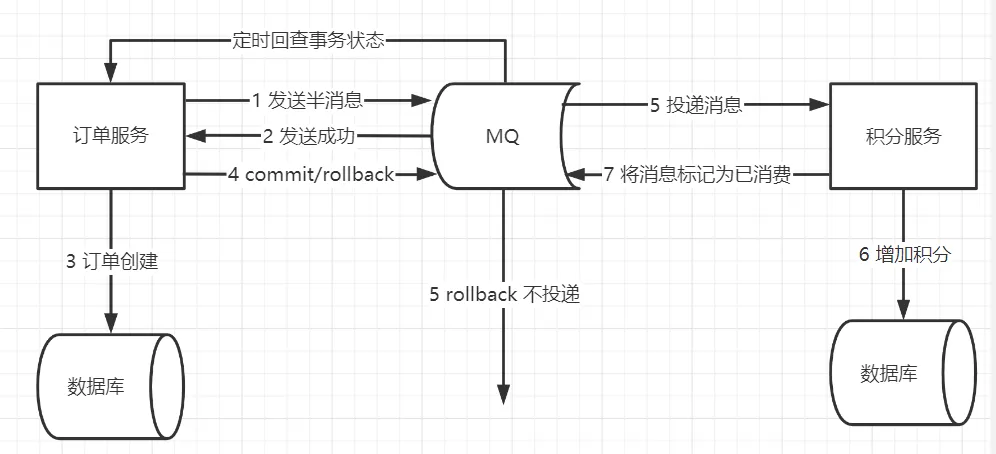
我们可以看到它的整体流程是比较简单的,同时业务开发工作量也不大:
编写订单服务里订单创建的逻辑
编写积分服务里增加积分的逻辑
可以看到该事务形态过程简单,性能消耗小,发起方与跟随方之间的流量峰谷可以使用队列填平,同时业务开发工作量也基本与单机事务没有差别,都不需要编写反向的业务逻辑过程
RocketMQ 事务消息 的价值
RocketMQ 事务消息 主要用于解决分布式系统中,消息发送与本地事务执行的一致性问题、原子性问题。
而 RocketMQ 消息的有点是:异步的、高并发的。并发量可以轻松实现 10Wqps。
所以:
RocketMQ 事务消息可以作为轮子组件,基础组件, 放到 本地消息表的弱一致性事务方案中,替代mysql形式的本地消息表,解决数据库操作的吞吐量低、性能低问题。
基于单向事务消息 的本地消息表方案
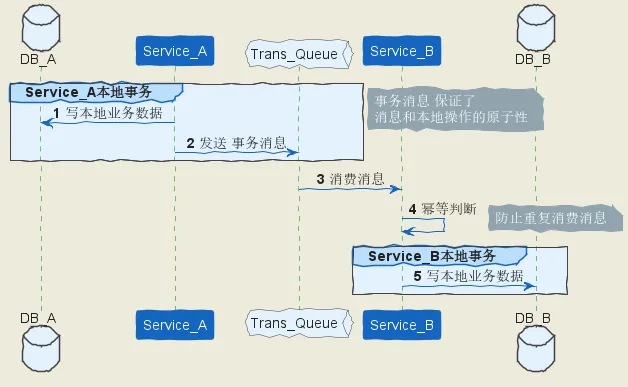
通过 单向事务消息 实现 分布式事务 的一般步骤:
消息生产方(也就是发起方), 事务消息和业务数据要在一个事务里提交,通过事务消息和本地事务结合,保证 消息发送的原子性、一致性。
消息消费方(也就是发起方的依赖方),需要处理这个消息,并完成自己的业务逻辑。此时如果本地事务处理成功,表明已经处理成功了,如果处理失败,那么返回Consume_later 。所以,如果是业务上面的失败,broker 后面会给消费方 重新投递,直到 消费方 消费成功为止。
事务数据的延迟消息对账
使用 Rocketmq消息topic 代替数据库的表本地消息表 ,如何进行 事务数据的定时对账,保证最终一致性呢?
答案是:可以结合Rocketmq 延迟消息,并且进行事务数据的查询和对账
基础知识:RocketMQ 中 延迟消息
在 RocketMQ 中,延迟消息是一种特殊的消息类型。
生产者在发送消息时可以设置消息的延迟级别,消息发送后会先存储在一个特殊的延迟消息队列中。
根据设置的延迟级别,消息会在相应的延迟时间后才会被投递到目标主题(Topic)的消费队列中,供消费者进行消费。
可以直接在服务器端的 broker.conf 中进行配置,在服务器端(rocketmq-broker端)的属性配置文件中加入以下行,但是这种方式不够灵活,不推荐。
|
这个配置项配置了从1级开始,各级延时的时间,可以修改这个指定级别的延时时间;
时间单位支持:s、m、h、d,分别表示秒、分、时、天;
这个配置项配置了从1级开始,各级延时的时间,可以修改这个指定级别的延时时间;
默认值就是上面声明的,可手工调整,默认值已够用,不建议修改这个值。
RocketMQ 支持定时的延迟消息,但是不支持任意时间精度,仅支持特定的 level,例如定时 5s, 10s, 1m 等。其中,level=0 级表示不延时,level=1 表示 1 级延时,level=2 表示 2 级延时,以此类推。
延迟5分钟 的参考代码如下:
/** * 发送延迟消息 * @param text * @return */ public Object sendDelayMsg(String text) throws MQClientException, RemotingException, InterruptedException{ Message message = new Message(JmsConfig.TOPIC, “delay_order”,(“this is a delay message:” + text).getBytes());
|
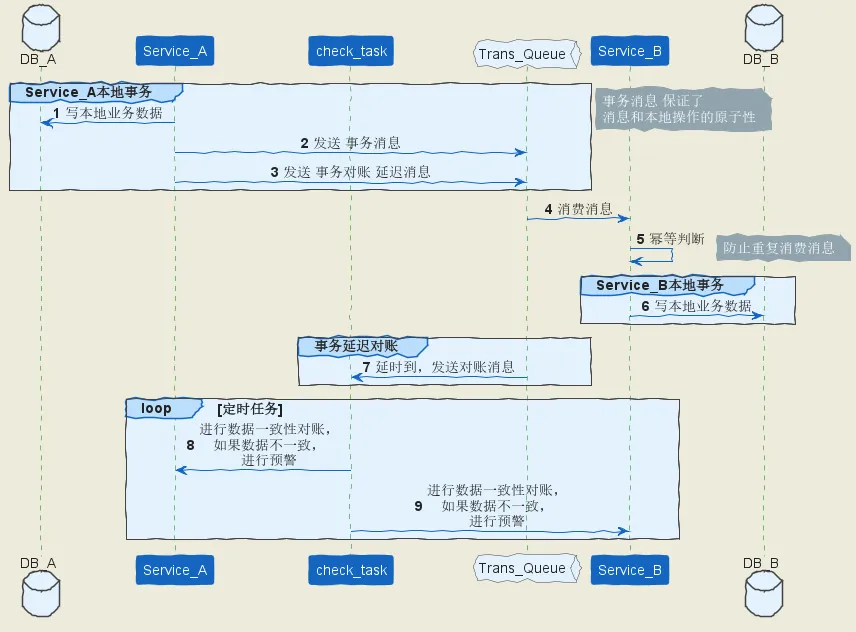
使用延迟消息,完成最终一致性对账
使用plantuml绘制的uml流程如,如下所示:
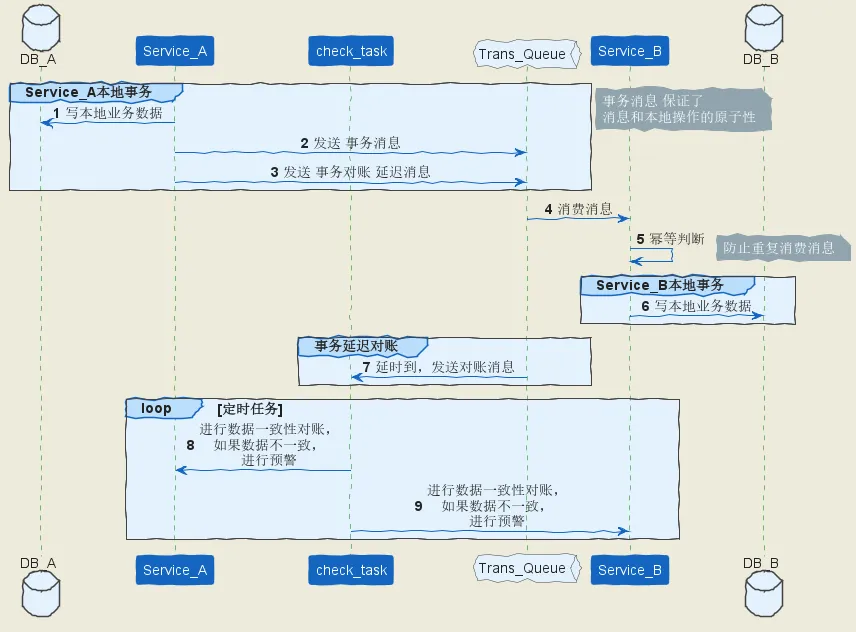
通过 单向事务消息 实现 分布式事务 的一般步骤:
消息生产方(也就是发起方), 事务消息、延迟对账消息、业务数据要在一个事务里提交,通过事务消息和本地事务结合,保证 消息发送的原子性、一致性。
消息消费方(也就是发起方的依赖方),需要处理这个消息,并完成自己的业务逻辑。此时如果本地事务处理成功,表明已经处理成功了,如果处理失败,那么返回Consume_later 。所以,如果是业务上面的失败,broker 后面会给消费方 重新投递,直到 消费方 消费成功为止。
设计一个延迟对账服务。延迟对账服务 收到 对账消息, 调用 Service_A 和 Service_B的对账接口进行对账,保证事务的一致性:如果 Service_A 和 Service_B都返回成功或者失败,则事务操作成功,如果 Service_A 和 Service_B返回不一致,则出现了数据不一致情况。创建业务处理的工单,业务人员介入进行数据的对账处理。
使用 plantuml 画 uml流程图,感觉非常方便,
建议大家用起来,多多画图。
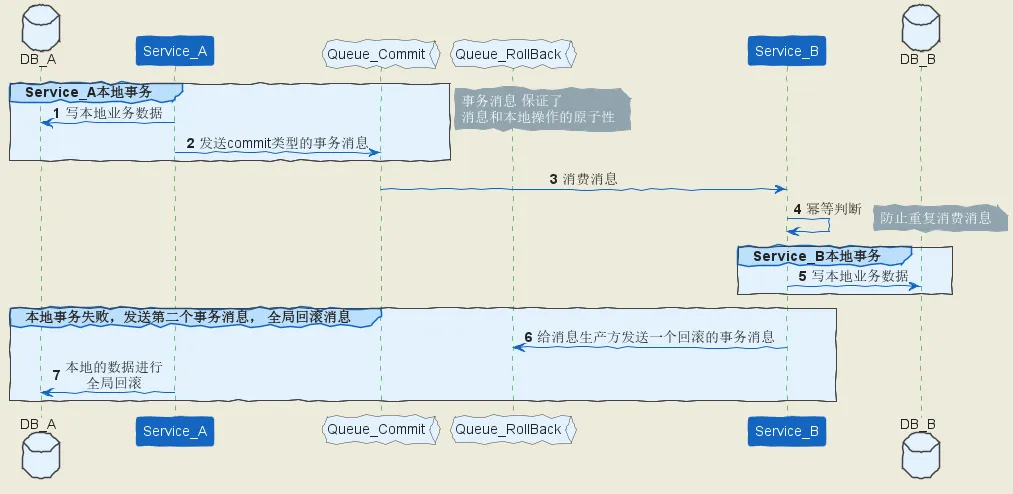
双向事务消息的本地消息表方案
上面是 生产者发单向消息,只能 生产者决定 提交、回滚, 消费者只能服从。
如果 消费者要求回滚, 怎么办呢?
解决的办法是:新增一个 反方向的 事务消息队列, 进行回滚的分布订阅, 事务的所有参与方进行订阅。
如果 消费者要求回滚,发布回滚的 消息就可以了。
这就是 双向事务消息 的架构。
具体如下图所示:
10Wqps 本地消息表事务架构方案大总结
最终,通过引入一个中间的Rocketmq承担本地消息表的职责,除了解决事务的一致性外,同样可以解决消息的丢失与幂等性问题,一举多得。
而且从业务的健壮性与数据一致性来看,一般都会增加一个补偿机制, 实现数据的 最终一致性。这也是BASE理论所支持的。


